使用Python编写并部署个人静态博客:(三)搜集博客数据
使用Python编写并部署个人静态博客:(二)实现静态页面的输出
使用Python编写并部署个人静态博客:(四)逐步输出静态页面
使用Python编写并部署个人静态博客:(五)Python异步输出博文页面
搜集博客数据
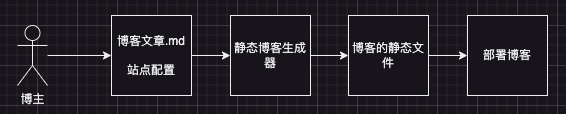
博客的静态页面的生成都是由博客的基础数据支撑的,搜集博客的基本信息和博客文章数据,是生成博客静态文件的核心功能。
博客的基础配置
每个博客都会有一些最基础的配置,例如博客的名称、简介、站长的昵称头像等,我们可以把这些基础的数据设置为一个配置文件,这里我使用了JSON格式的配置文件。可以在站点的根目录下创建一个config.json,其内容格式大概如下,可以根据自己的需要添加修改。
{
"dev": 0,
"blog_name": "碎言博客",
"blog_name_en": "SuiYan",
"blog_author": "J.sky",
"blog_description_en": "You see see you , This one day day di.",
"blog_typed": [
"Life is short, you need Python",
"人生苦短,我用Python.",
"Beautiful is better than ugly.",
"美丽优于丑陋.",
"Explicit is better than implicit.",
"直白优于含蓄.",
"Simple is better than complex.",
"简单优于复杂.",
"Complex is better than complicated.",
"复杂优于繁琐.",
"Readability counts.",
"可读性很重要."
],
"meta_description": " Python Django JavaScript 学习讨论,我们是一群热爱Python的程序员,人生苦短,我用JavaScript!一个不会JavaScript的Python开发者不是一个好网管。",
"meta_keywords":"Python,Django,JavaScript,程序员,人生苦短,我用Python",
"profile_image":"assets/images/avatar.jpg",
"blog_bg": "assets/images/bg.jpg",
"theme": "my_blog",
"build": "blog",
"md_dir": "articles",
"blog_page_num":8,
"blog_test_url":"http://127.0.0.1:5501/",
"blog_url":"https://suiyan.cc/",
"blog_sns": [
{
"ico": "github",
"url": "https://github.com/bosichong/suiyan"
},
{
"ico": "git",
"url": "https://gitee.com/J_Sky/suiyan"
},
{
"ico": "envelope",
"url": "mailto:285911@gmail.com"
},
{
"ico": "book",
"url": "https://www.zhihu.com/people/J_sky/activities"
},
{
"ico": "rss-square",
"url": "https://suiyan.cc/rss.xml"
}
],
"nav": [
{
"ico": "home",
"text": "Home",
"url": ""
},
{
"ico": "archive",
"text": "Archive",
"url": "archives.html"
},
{
"ico": "tags",
"text": "Tags",
"url": "tags.html"
},
{
"ico": "user-md",
"text": "About Me",
"url": "aboutme.html"
},
{
"ico": "link",
"text": "Links",
"url": "links.html"
}
]
}
然后就可以在程序的文件中组织这些最基础的配置,例如提取文件地址和内容,分配静态文件生成发布的目录等,使用一些常量来定他们,放到代码的最顶部。
APP_CONFIG = "config_my.json"
BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # 当前目录地址
CONFIG = load_configjson(os.path.join(BASE_DIR, APP_CONFIG)) # 获取当前配置
BLOGPAGES = os.path.join(BASE_DIR, CONFIG["build"]) # 所有静态资源存放目录
ARTICLES_DIR = os.path.join(BASE_DIR, CONFIG["md_dir"]) # 博文目录
THEME = os.path.join(BASE_DIR, "theme") # 主题目录
CONFIGJSON = os.path.join(BASE_DIR, APP_CONFIG)
BLOGCONFIG = os.path.join(BLOGPAGES, 'config.json')
BLOGDATAJSON = os.path.join(BLOGPAGES, 'blog_data.json')
SUIYANVERSION = "3.1.0" # 程序版本
通过Python读写文件的操作,定义一个方法从磁盘上来获取config.json的内容并转化为Python的字典:
def load_configjson(jsonpath):
"""载入blog配置文件config.json"""
config_code = loadcode(jsonpath)
config = json.loads(config_code)
return config
具体的代码可以查看碎言静态博客的代码仓库,这里只介绍一些项目的架构技巧。
博客文章以及其他相关数据的搜集
博客的静态文件除了基础的博客信息外,还有博客的归档、分类(标签)、博客页面的数据等,这些都需要从博客文章的Markdown文件数据集中计算得出。 这里我采用了从文章目录中搜集博客文章,读取文章头部的定义内容,组织这些数据创建一个blog.json的索引,这个索引可以用来生成归档和标签页面的内容,也可以用来作为搜索的依据。
具体通过递归扫描文章目录来生成:
def create_blogdata_json(adir):
"""
递归获得当前目录及其子目录中所有的.md文件列表。
并创建blog的data索引JSON
:param adir: 文章日志所在目录
:param bdir: 站点根目录
:return: json字符串
"""
data_json = []
# 当前目录下所有的文件、子目录、子目录下的文件。
for root, dirs, files in os.walk(adir):
for file in files:
# 值读取.md
if file.endswith('.md'):
url = os.path.join(root, file).replace(
adir + os.sep, '').replace('.md', '') # 最后需要组装的相对目录
furl = os.path.join(root, file) # 当前文件的绝对目录
f_data = extract_md_header(furl) # 获取.md的文章信息转成字典
f_data["url"] = url
f_data["uptime"] = get_file_modification_time(os.path.join(root, file))
data_json.append(f_data) # 添加到需要返回的数据数组中
data_json.sort(key=lambda x: x["time"], reverse=True) # 对数组进行降序排序
data_json_str = json.dumps(data_json, ensure_ascii=False) # 转化为json字符串
return data_json_str
有了这个文章数据之后,基本上就是解决了所有的静态博客文件生成依赖了。之后我们就可以编写代码,依次或是批量生成相关的页面了。